milieau.04 designing the crawler app
specifying unknowns from requirements
First off I must specify the generalized statements made in the functional requirements for the crawler, which will inform the design process.
datatype / formulation
As according to the functional requirements, the crawled data must be in a machine readable format. Now that I’ve relearned a bit of pandas and further geopandas, I think CSV is a good solution, because it can be directly parsed into a pandas DataFrame, while being human and machine readable.
The output file should be named uniquely for each run of the program. YY-MM-DD-HH-MM_SITEand the file structure should be such that sites are differentiated and the validation status is differentiated between validated and - (not validated).
milieau-analysis/crawler/data/validated/
necessary data to crawl for
Necessary is a tricky word to define, but I will try to do so by referencing remax.fi apartment listing “Perustiedot” (basic info) section. Here’s a screenshot from a listing in Turku active currently:
 All in all, the Perustiedot section amasses 197 lines of data, with the titles for each datapoint being on their own lines, so approximately 98 datapoints per listing. I’m not sure if all listings have to have such a broad description, probably not, but considering that on remax there are only listings made by professional real estate brokers, the listings should all be quite descriptive.
All in all, the Perustiedot section amasses 197 lines of data, with the titles for each datapoint being on their own lines, so approximately 98 datapoints per listing. I’m not sure if all listings have to have such a broad description, probably not, but considering that on remax there are only listings made by professional real estate brokers, the listings should all be quite descriptive.
I’ll cull the datapoints that don’t pass these requirements:
- easy to parse (quantitative or categorical)
- describes the apartment
Here are separated, culled, kept and maybe values:
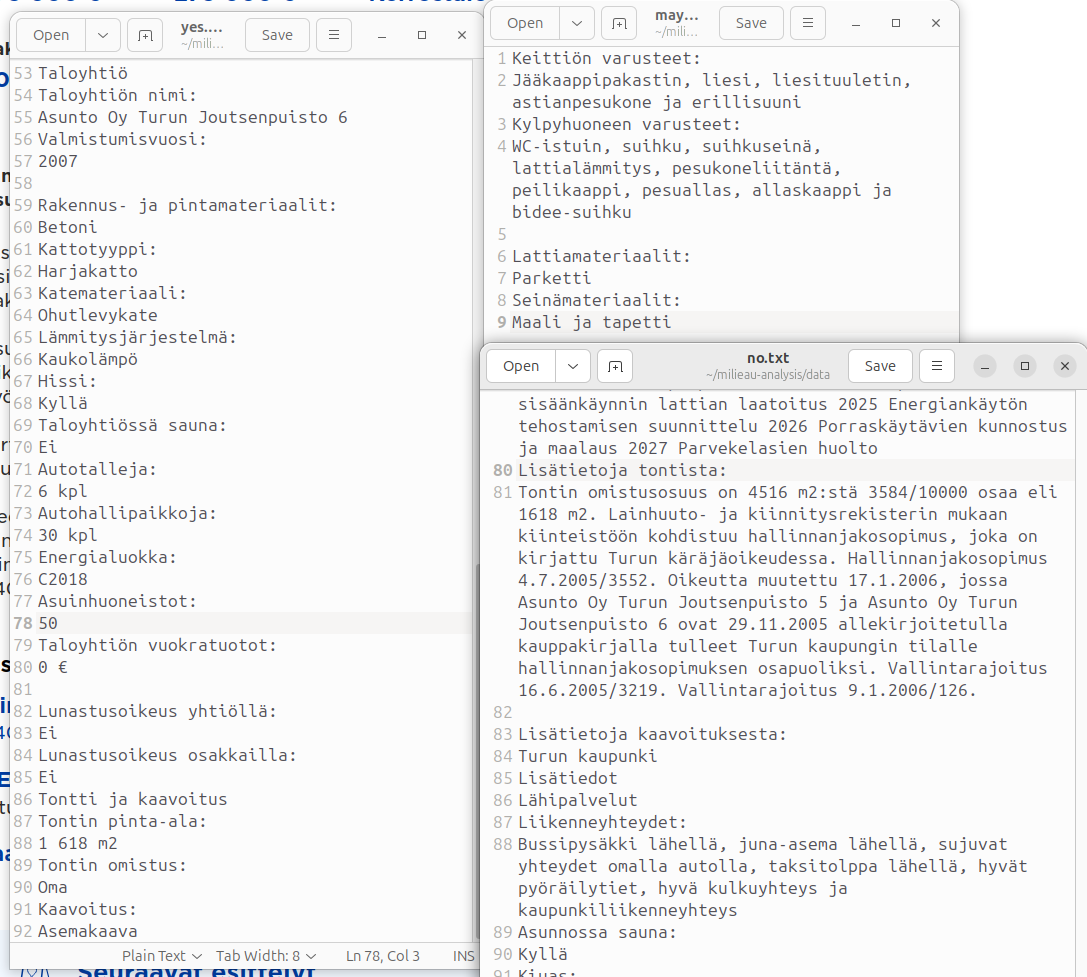
Overall there were quite a few repeated values. I also culled some values that possibly affect the value of the property and the desirability of the property without necessarily affecting the value. These minute things would be nice to know, but I will exclude them, as I feel my dataset is too limited to benefit from them.
Having thought about it, I won’t exclude them, because they aren’t harming anyone if they are there. In the end the selection process is quite personal, and I couldn’t set strict boundaries. The end result is 87 lines of data and accounting for the headers its around 40 values. A lot, but a lot less than 90.
websites
My aim is property listing sites, where crawling is not prohibited in their TOS. This includes at least Re/max, I suppose other smaller (compared to oikotie or etuovi) providers have a similar stance (no stance). But I will start by focusing on Re/max.
The other thing about crawling specific real estate agencies is that they might have a focus of their own, so one agency might not be representative of the whole set (turku centre). This causes a bit more work / uncertainty.
- It might necessitate including in the dataset a mark about where and when the datapoint was collected
CLI interface
It will most likely look something like this:
$~ ./milieau-analysis.py [source url, with CGI filters to Turku center] [output file] -[arguments: --append, --debug]
If I want to run the same script in regular intervals I’ll use crontabs, nothing fancier is necessary.
Best practices are to save new retrievals to their own file, and I can then manually include them in the proper table, once they are validated manually.
validation
Two points for validation, I need a crosscheck for checking that the same property isn’t on there twice and a validation that the retrieved data is formed properly.
- Because address strings might not be typed the same way and therefore string compare isn’t such an easy task, crosscheck will be done primarily through the geocoded coordinates
- If they are the same then the descriptive properties are compared line by line, and if there are no differences (in the attributes both datapoints contain), the newer one is discarded.
- Proper formulation of data can be done by limiting datatypes in the class constructor for the datatype.
- If an attribute can’t be converted, for example, from string to int, the whole datapoint is appended to another CSV and not included with the data that passes the validation.
code structure
After thinking and jotting down extensive and sporadic notes on how to organize the file structure I came to these modules:
cli
- gets summoned when the program starts
- printing formatting
- handles CLI arguments
- decides system behaviour based on them I think I will use argparse for this
htmlparser
- parses HTML files
- used to parse the listing_list type html file and property listing type html file
- parses the listinglist.html for elements containing links to listings, extracts the links to a list and saves the list to a separate text file for the crawler to read
- parses the propertylisting.html files once the crawler has returned them for property attributes defined in propertysite class
- extracts those attributes to a dataframe
- the cli arguments define the parses behaviour, or the propertysite class does.
- adds columns to the dataframe for: propertyID (from URL), siteID (eg remax), sessionID (datetime)
propertysite
- an abstract base class to define all functionality necessary for different sites, since the implementations of those sites differ, we have to have different class implementations.
- is used in htmlparser for it to know what elements contain necessary data
- is used in crawler for it to know which element needs to be clicked for it to surf to next page Things needed for this
crawler
- accessess the listing list sites
- surfs all pages of listings
- downloads the listing list sites as one big site / appends each page to the end of the listinglist.html file
- surfs the propertylisting links collection and downloads each property listing as html to its own html file.
datahandler
- accepts the dataframe returned by htmlparser, validates all datapoints for wholeness and appropriate datatypes.
- extracts the noncorforming rows to another dataframe
- this is saved as a separate csv
- if there are noncorforming rows, the exception handler prints all rows of noncorforming data, if not it should print that there were non. Maybe it should be like this:
"{len(nonconforming)} number of bad rows: \n {pd.display(nonconforming)} \n" - these can be checked by hand later, corrected, geocoded and inserted into the dataset later
- converts df to Geodf
- adds columns to the dataframe for: coordinates
- geocodes addresses
- crosschecks the coordinates for duplicates
- and sendst the newer one to another dataframe called duplicates them if they are indeed the same apartment, same size, same floor (if applicable), same price etc
- that df is again saved as csv
tests
I will be writing unit tests for all functionalities as I go along most likely using unittest, testing all code before I commit it, or atleast before I push it.
dataflow diagram
Maybe this is more like control flow, but whatever.

file structure
I find that it is kind of dangerous to have all data in the same directory tree, they might all get yeeted if something happens. I’ll try to use syncthing to backup both my data folders to my other device. That way if something happens everything doesn’t explode.
~/milieau-analysis/
data/ # for validated GeoDFs
validated.gdf
# same data as validated.gdf but separated by sessions
{site}_{session}.gdf
crawler/
main.py
src/
__init__.py
cli.py
htmlparser.py
datahandler.py
propertysite.py
crawler.py
tests/
__init__.py
data/ # for unvalidated GeoDF + html
{site}/
{session}/
listinglist.html
{propertyID}.html
nonconforming.gdf
duplicates.gdf
cleaned.gdf
analysis/ # not relevant for this
{site} comes from url, like remax
{session} is YY-MM-DD-HH-MM, the timestamp is taken whenever script is run, so that the timestamp stays consistent across result files.
{propertyID} comes from url as well, its the last section of the url that points to the property listing.
I’m still not sure about how the structure should be relating to __init__.py and how should i name the main script and the src folder. More relevant names would be nice, but it probably doesn’t matter that much.
Otherwise I think that structure is fairly good.